ETL vs. ELT: Understanding the differences & benefits
.webp)

Today’s businesses generate data from a multitude of sources, including production databases, SaaS applications, their website, analytics tools, and more. And when you have data from several different sources that you want to use for analytics and business intelligence, you can’t just load all of that raw, unstructured data into your data storage system and call it a day.
There’s a critical step that needs to happen first: ETL or ELT.
Both acronyms refer to the data integration process that turns raw data into clean, structured data that can be loaded into a storage system (generally a data warehouse), where it will then be
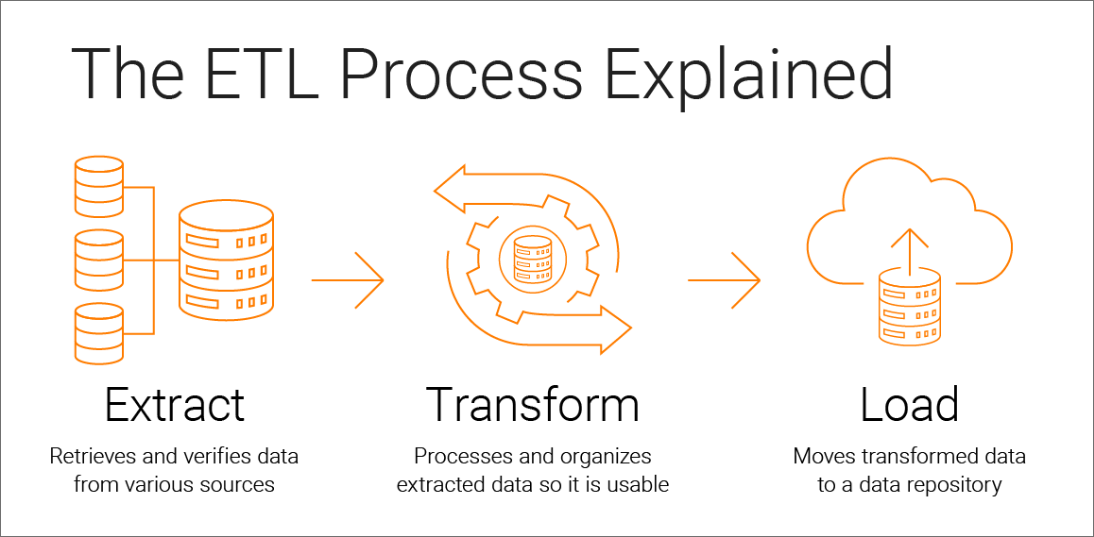
Whether you're using ETL or ELT, you need to:
✅ Extract raw data from a source, like a SQL database or SaaS tool
✅ Transform the data, which involves cleaning it up, processing it, and converting it to fit existing formats in your data storage location
✅ Load the data into your data warehouse to enable future analysis
Extraction always comes first, but ETL and ELT perform the transformation and loading phases in a different order. With ETL, data is transformed before loading it into the data warehouse. With ELT, transformation happens after it’s been loaded.
That’s the simplified version, but before you can answer the question “What are the differences between ETL vs. ELT and what do they mean for my organization?” you need to understand each process in greater detail:
- What is ETL?
- What is ELT?
- A quick comparison of ETL vs. ELT
- ETL vs. ELT: When should you use ETL instead of ELT (and vice versa)?
- Which data integration tool should you use?
- Data operationalization: The ultimate goal
We’re also going to share some use cases so that you understand how these concepts play out in the real world. After reading, you’ll have the information you need to make an informed decision about processes and tooling.
What is ETL?
ETL (Extract, Transform, Load), where data is extracted from a source, transformed on a secondary processing server, and loaded into a data storage system, has been around since the 1970s.

In the beginning, ETL processes were hand-coded by data engineers. Now, ETL tools like Fivetran, Matillion and Airbyte automate the process.
Benefits of ETL
These are some of the top benefits of using the ETL process for data transformation:
Lower storage costs for your data warehouse. ETL tools only transform and store the data you need which can reduce the overall costs of data storage.
Compliance with security protocols and regulatory requirements. If your organization needs to comply with regulations that require removal, masking, or encrypting certain information, ETL may be a good fit because you can remove any sensitive data before storing it in your data warehouse.
ETL is a mature process. Since ETL has been around for decades, it's a well-understood process that data engineers are familiar with.
Less limited by SQL. Complex operations and large scale data manipulation can be done much more efficiently using Python instead of SQL, but most ELT processes rely on the power of a data warehouse and SQL to perform data transformations. On the contrary, ETL flows can (and usually do) include non-SQL transformations.
Speedier analysis. When you have predefined use cases with datasets that have already been structured and transformed, analysis can happen immediately once the data is loaded into your warehouse. A great example of this is Fivetran’s Zendesk ETL process (using dbt) which will create a clean set of models, ready for business users to get the valuable answers they need.
Transparency of your data lineage. With ETL, data lineage (the complete life cycle of your data as it moves from sources to consumption by end-users) is more clear-cut and easy to map.
Disadvantages of ETL
ETL isn’t without disadvantages, however:
Higher startup and maintenance costs. Ideally, you’ll define all of the processes and transformations that you’ll need at the very beginning. That takes time, human resources, and financial resources.
However, no matter how inclusive that initial setup is, things are bound to change. New use cases, new data connections, broken data connections, and requests for new features (such as new columns and dimensions) are all likely.
When that happens, the ETL process will need to be repeated again.
Slower data ingestion process. Since data is transformed on a separate server before it’s loaded into the data warehouse, you need to wait until the transformation step is finished before loading can begin.
This may not seem like a big deal, but it can quickly become a problem when you’re working with large amounts of data. Let’s look at a growing ecommerce brand as an example. In the beginning, all of the data can be extracted, transformed, and loaded into the data warehouse with an ETL process that runs overnight. Production data, supplier data, customer data, financial data, marketing data, and more are all manageable.
But, as the company grows, so does the amount of data it collects. Suddenly, there’s not enough time for the ETL process to run successfully every night. Before you know it, complaints about incorrect inventory and other issues start coming in. Yikes.
Less flexibility. With ETL, you need to configure the transformations for format changes and potential edge cases ahead of time. Otherwise, the ETL process will have to be modified for every edge case that pops up.
Making those predictions ahead of time isn’t easy because you need to think through uncommon and unexpected scenarios. For example, when thinking about inputs for date fields, the entire possible range of dates needs to be accounted for, including leap years.

Lack of flexibility is also a problem if your data sources and formats change often.
ETL workflows can be finicky. This is another example of the rigidity inherent in ETL, but it’s worth a callout. For ETL to work properly, all of the parameters in your workflows must be well-defined. If one step in an ETL workflow breaks it can easily break other workflows in the chain.
Fortunately, there’s an alternative to ETL that solves many of the issues described above.
What is ELT?
ELT (Extract, Load, Transform) describes the data integration process where data is extracted from a source, loaded into a storage system, and transformed inside the storage system. A staging area isn’t needed since the transformations occur once the data is in your warehouse, data lake, or another storage system.
ELT first came on the scene with the evolution of cloud computing in the 2000s. It provides a more accessible, affordable, and scalable way for companies to perform sophisticated data analyses.
Modern organizations collect, process, store, and analyze a massive amount of data in a range of formats. They need to make time-sensitive decisions in a fast-moving business landscape, as quickly as possible. ETL isn’t the most reliable or efficient way to accomplish those goals, which is why ELT is gaining popularity.

Benefits of ELT
Here are some of the reasons your organization might consider ELT for its data integration needs:
It’s fast. ELT tools speed up the data ingestion and transformation process because data can be quickly loaded into your storage system and then transformed directly inside of that system.
ELT is inherently flexible. Since transformation is the last step in the process, your data team has the freedom and flexibility to transform data to meet the needs of your end-business users, even if those needs change and evolve. This solves a lot of the rigidity problems we explored earlier.
Additionally, if the amount of data you need to integrate increases or decreases, ELT processes can adapt (versus an ETL process that may need refining as the workflow changes.)
It saves time. You can transform data directly inside of your warehouse, which offers substantial time savings. How much time? Quite a bit, actually.
Don’t take our word for it, though. Here’s what David Krevitt, Head of Acquisition at dbt had to say about ELT in his article, A love letter to ETL tools:
“Being able to transform data directly in the warehouse would’ve saved my team thousands of hours per year in aggregate (1hr per person per week x 100 people conservatively), as we could’ve rerun only the transformations that were affected by a change.”
Initial costs are lower than ETL. ELT tools do a great job of automating the data onboarding process and there’s no need to painstakingly define all of your transformations at the beginning (which ties into the flexibility benefit we mentioned earlier).
Disadvantages of ELT
ELT isn’t without disadvantages, though, and they’re worth noting;
Data security risks. Security can be an issue when loading raw data into your storage system. But, these risks can be mitigated with the right security protocols, like managing user and application access for raw data that’s stored in your data warehouse.
Compliance with compliance and regulatory requirements is lower. This is because data is stored with minimal processing.
With ELT, you may need to take extra steps to remain compliant with data security protocols if your company is subject to specific regulations, like HIPAA (Health Insurance Portability and Accountability Act) or SOC 2 (Service Organization Control 2).
Many data warehouses do have integrated security protocols to support compliance. If you opt to use ELT, be sure to pay careful attention to security and regulatory compliance standards when vetting systems and tools.
A quick comparison of ETL vs. ELT
That’s a lot of information to process, so here’s a summary of the primary differences between ETL and ELT:
ETL vs. ELT: When should you use ETL instead of ELT (and vice versa)?
Some people mistakenly assume that the benefits of ELT mean there’s no place for ETL in a modern data stack, but that’s hardly the case.
ETL is best for:
Advanced analytics. For example, data scientists working on connected cars need to load data into a data lake, combine it with another data source, and use it to train predictive models. In this case, having unprocessed data is more efficient because it reduces unnecessary data movement.
Compliance. For example, a healthcare company that needs to remove personally identifiable information before loading data into its warehouse to comply with HIPAA.
ELT is best for:
Large data volumes when speed is important. For example, companies that have a lot of data to process, like the growing ecommerce brand we used as an example in the Disadvantages of ETL section. Realistically, though, this could be a benefit for any data-driven organization.
Flexibility. If you need a flexible data integration process to accommodate data sources and formats that change frequently, ELT is a solid choice. There’s no need to figure out how to structure the data before it's loaded into your warehouse because data modeling can take place as needed.
At the end of the day, you need to consider the data you have and the long-term needs of your company when choosing a data integration solution.
Which data integration tool should you use?
This topic deserves a blog post of its own (and it’s something we’ll cover extensively in the future) because there’s no shortage of ETL/ELT tools that you can use for data integration.
For the sake of simplicity, here’s what we often recommend:
Once you understand the differences between ETL vs. ELT and have chosen a data ingestion tool, there’s still one more step you need to take to get the most out of your data: data operationalization.
Data operationalization: The ultimate goal
Data operationalization, which is also referred to as data activation and reverse ETL, should be the end goal of all data-driven organizations.
When data is operationalized, it’s integrated into a company’s day-to-day workflows and core business systems.
Data Operationalization: What happens when everyone in an organization can seamlessly access, understand, and build with the data they need in the core operating documents they know and love, like Google Sheets, Notion, and Airtable 🙌.
Data operationalization is achieved during the last step of the data stack building process. In the past, support from data and engineering teams was the only way to make it happen.
Times are changing, though.
Reverse ETL tools are opening up new possibilities for everyone in a company, including non-technical end-users. These tools use the power of “no-code” to bring self-service data analytics to the masses, allowing people to build the analyses, workflows, and data tools they need in a secure way that can scale with their needs.
What could you accomplish by operationalizing your business data?
At AirOps, we’re on a mission to help everyone experience the possibilities of data operationalization. If that sounds like something you want to get in on, click here to make sure you receive our latest updates.
In the meantime, brainstorm some answers to the question, “What could you accomplish by operationalizing your business data?” so that you’re ready to get started when we launch!
Scale your most ambitious SEO strategies
Use AI-powered workflows to turn your boldest content strategies into remarkable growth



{kind=link}