dbt exposures: A powerful [and underused] feature

Do you have visibility into how and where your data is being used? If not, you could be courting disaster. At the very least, not knowing how data flows through your organization will make your life harder than it should be.
Without downstream visibility into how, how often, and where data models are used, you risk running into a whole host of issues that will cause you and your data team to…
- Fly blind to the potential downstream impacts that changes you make to data models might have.
- Struggle to tie business value to a particular model
- Waste time reverse engineering the source of a particular analytics asset.
No final mile visibility also hurts your engineers – without it, they can’t understand exactly how their work powers the business. Time management is also a lot more difficult since engineers don’t have the context they need to prioritize the most important and impactful work first.
If you can't see where and how your data is used, you also risk wasting precious time attempting to reverse engineer dependencies between data sources and downstream data assets when something breaks.
I’ve experienced these problems firsthand, so when dbt launched a powerful new feature called exposures in late 2020, I was immediately excited.
Even though exposures is a powerful feature that can help data teams maintain good data visibility practices, I’ve noticed it’s still somewhat underused by the broader dbt community. I think I know the reasons for this lack of adoption – for starters, defining exposures is typically a manual process.
The good news is that there are ways to automate exposures 🎉. I’ll cover exactly how in the Automate your dbt exposures section, but first, let’s take a closer look at…
- What dbt exposures are
- Why they’re valuable
- Why they aren’t used more widely
- How to set up your dbt exposures
What are dbt exposures?
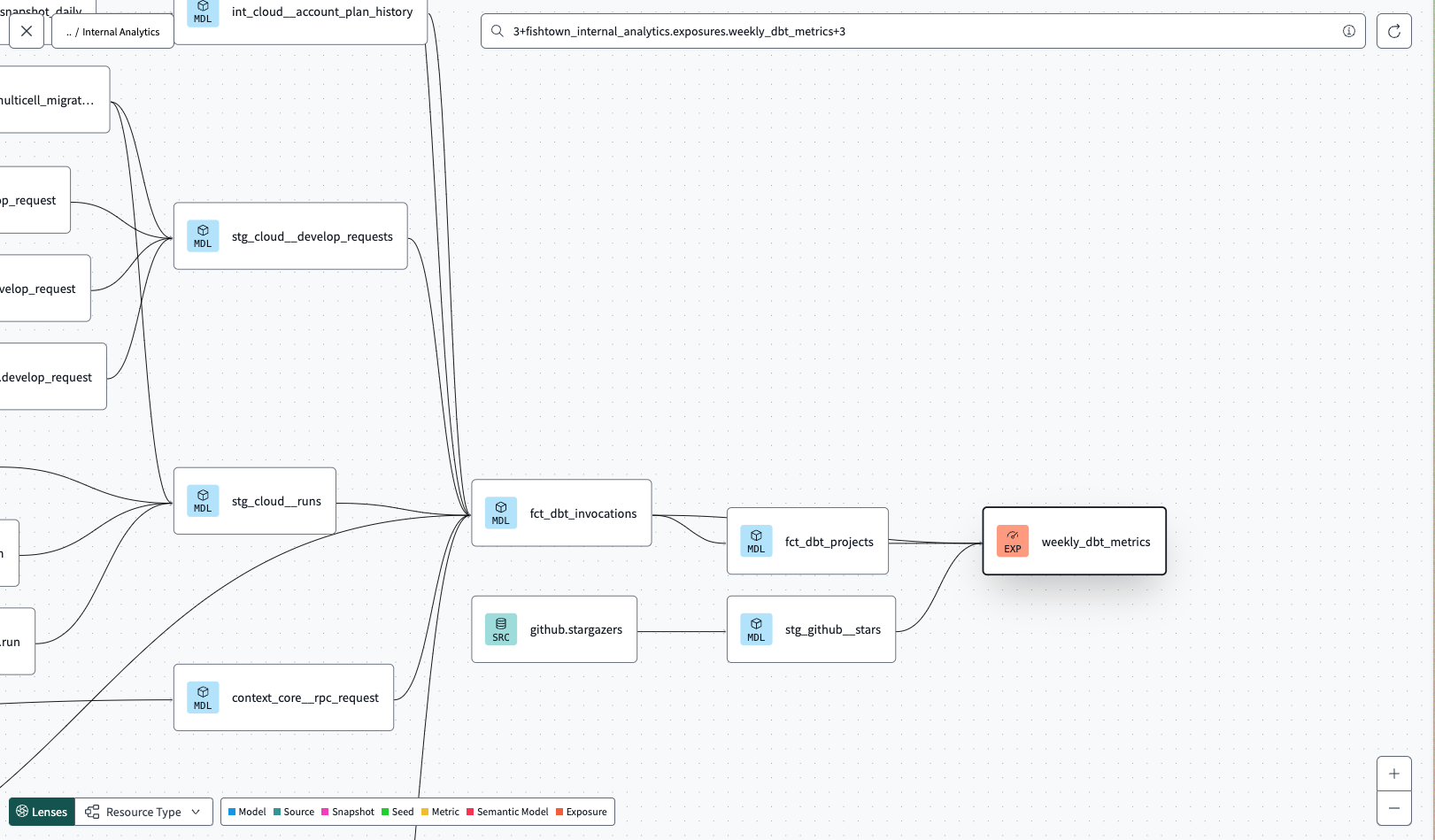
Exposures allow users to define downstream uses of a dbt project, and they’re a relatively new dbt feature (they were released with v0.18.1 in late 2020).
Here’s how dbt describes exposures:
“Exposures make it possible to define and describe a downstream use of your dbt project, such as in a dashboard, application, or data science pipeline. By defining exposures, you can then run, test, and list resources that feed into your exposure.”
In the lineage graph, or DAG (directed acyclic graph), that dbt generates you can see how data flows from the original data sources (green nodes, far left), to staging tables (blue-ish nodes, middle), to exposures (orange-ish nodes, far right). Everything to the left of the exposure is an upstream dependency.
The DAG isn’t just for data teams, either. These graphs are easy to understand and aren’t overly technical, so you can share them with business stakeholders to show how data assets are used throughout the organization. This can be an effective (and easy) way to demonstrate the impact of analytics.

Why are dbt exposures valuable?
At the beginning of this article, when I said that a lack of data visibility is “courting disaster,” I wasn’t being hyperbolic. Final mile data visibility is critically important for data teams that want to deliver value and generate positive ROI for the business.
Exposures also help you…
🌊 Understand the downstream impact of changes made to data models.
When you declare an exposure, it generates straightforward visibility into all of the tables that are using your dbt models. You can reference the DAG lineage graph to easily determine how potential changes might impact your models.
⏪ Save time, because there’s no need to reverse engineer the source of an analytics asset.
This one is fairly self-explanatory, but it’s still worth a callout – because dbt exposures provide full visibility into the upstream uses of data assets, data teams can easily locate dependencies between data sources and downstream data assets, such as dashboards or connected Google Sheet financial models.
If something breaks, you can easily trace the source of the issue. Better yet, before you commit a change to prod, you can view and proactively communicate the change to the owner or consumer of any data product that the change will impact.
Exposures reduce the volume of “urgent” Slack threads and Jira tickets to find out that something broke.
⭐ “Macromanage” all of your runs based on the endpoint.
Exposures also allow you to evaluate, run, and test the data resources that exist upstream to the exposure. This comes in handy when you have a dashboard or application that requires more frequent data syncing than the rest of your dbt project and is a massive value-add.
Some background on why this is so cool → when you run dbt jobs, you run them by defining a target for the run. Conventionally, this would be the name of a model or a tag associated with several models. You can also run a model’s forward and backward dependencies. Until recently, I didn’t realize you can do that with exposures, too 🤯.
That means you can start from a sync or a dashboard that you’ve already created and run all of the things that depend on that dashboard automatically. If you have a high-priority piece of analytics that you want to execute at a specific time, it’s super easy to control from dbt when you have an exposure to do it from.
💸 Tie business value to a particular model and understand how, how often, and where data models are used.
Since exposures are endpoint nodes inside of the dbt project, each one will have a dedicated page in an auto-generated documentation website. This documentation:
- Includes all of the necessary context that’s relevant to data consumers, and;
- Helps downstream data consumers discover and better understand the context behind the datasets that the data team is developing.
This makes it easier for data teams to see how data is used within the company, which makes it possible to connect the dots between data and ROI.
Why don’t more people use dbt’s exposures feature?
Despite the value that exposures bring, they don’t always fit into an analytics engineer’s ideal workflow: Declaring exposures is a manual process that can only happen after you’ve built a data model.
Because of this, exposures are often an afterthought–something that the analytics engineer has to go back and do every single time they finish creating something. This isn’t a natural workflow, especially once business users are already using a dashboard or dataset.
It’s not surprising that the value of exposures often goes unrealized, even by analytics engineers who rely on dbt for the rest of their data transformation needs. Once a project has been delivered, most engineers want to get back to work and tackle the next task.
But, there is a way to automatically create exposures…
… AirOps 💥.
With AirOps + dbt, exposures automatically generate after a data model is built. There’s no need to switch up workflows or go back and add something to data assets that are already in use.
But, I’m getting ahead of myself – first, let’s go over how to define exposures in dbt.
(If you’re already familiar with how to set up exposures and want to learn how to automate them, jump to the Automate your dbt exposures with AirOps section.)
How to set up dbt exposures
Exposures are very simple to define. They follow a nearly identical process to defining metadata for models and sources and can be set up directly in .yml files. Metadata properties added to the sync record in the .yml file help provide additional context to the purpose of the exposure object.
In the example below, an exposure has been created for a sync job that loads data from a model containing Hubspot data. The exposure record has been added to the .yml file within the Hubspot directory of the dbt project.
A few notes:
- The only required properties are “name”, “type”, and “owner”.
- While not required, the “depends_on” property is also important to map the exposure back to the models from which it references data.
- Things like “url” and “description” also allow viewers of the exposure to understand its purpose and trace its location.
Here’s a rundown of all of the available exposure properties:
Required properties:
- name (must be unique among exposures and you must use the snake case naming convention)
- type: one of dashboard, notebook, analysis, ml, application (used for organization purposes in your generated documentation site)
- owner: email
Expected properties:
- depends_on: list of refable nodes (ref + source)
Optional properties:
- url: enables the link to View this exposure in the upper right-hand corner of the generated documentation site
- maturity: one of high, medium, low
- owner: name
General properties (optional):
- description
- tags
- meta
After the exposure has been defined in the .yml file it can be viewed in the lineage graph and docs, and commands can be run that reference it.
For example, to run all models that the hubspot_sync depends on, the following commands can be used:
dbt run -s +exposure:hubspot_sync
Now, all upstream models will update!

When all exposures are consistently defined in dbt, analytics engineers can resolve data visibility issues and quickly identify how changes to the data model may result in problems downstream.
Soon enough, you’ll soon have a complete picture of your organization’s data landscape.
Automate dbt exposures with AirOps
With AirOps, you don’t have to worry about staying on top of creating exposures, because AirOps generates dbt exposures automatically.
By creating a pull request to the dbt repository, AirOps both notifies the analytics engineering team of new syncs that have been created and allows the team to review and approve the update before merging.
With AirOps + dbt, you can…
- See where data is flowing, down to the spreadsheet, dashboard, or Airtable base
- Receive notifications when new data assets are connected
- See exposures inside of dbt and link those exposures to your AirOps assets
- Orchestrate the refresh of your models directly to the sync in AirOps
Compare that to a dashboard, where data teams need to create every exposure after the fact, once the dashboard has already been created and delivered. That’s not a very effective or efficient process. Plus, it requires a level of data hygiene that’s difficult for many teams to achieve.
Scale your most ambitious SEO strategies
Use AI-powered workflows to turn your boldest content strategies into remarkable growth
.webp)



.webp)
{kind=link}